I recently used Jacquard to write an AppView Index for Weaver. I alluded in my posts about my devlog about that experience how easy I had made the actual web server side of that. Lexicon as a specification language provides a lot of ways to specify data types and a few to specify API endpoints. XRPC is the canonical way to do that, and it's an opinionated subset of HTTP, which narrows down to a specific endpoint format and set of "verbs". Your path is /xrpc/your.lexicon.nsidEndpoint?argument=value, your bodies are mostly JSON.
I'm going to lead off by tooting someone else's horn. Chad Miller's https://quickslice.slices.network/ provides an excellent example of the kind of thing you can do with atproto lexicons, and it doesn't use XRPC at all, but instead generates GraphQL's equivalents. This is more freeform, requires less of you upfront, and is in a lot of ways more granular than XRPC could possibly allow. Jacquard is for the moment built around the expectations of XRPC. If someone want's Jacquard support for GraphQL on atproto lexicons, I'm all ears, though.
Here's to me one of the benefits of XRPC, and one of the challenges. XRPC only specifies your inputs and your output. everything else between you need to figure out. This means more work, but it also means you have internal flexibility. And Jacquard's server-side XRPC helpers follow that. Jacquard XRPC code generation itself provides the output type and the errors. For the server side it generates one additional marker type, generally labeled YourXrpcQueryRequest, and a trait implementation for XrpcEndpoint. You can also get these with derive(XrpcRequest) on existing Rust structs without writing out lexicon JSON.
/// Endpoint type for
///sh.weaver.actor.getActorNotebooks
;
As with many Jacquard traits you see the associated types carrying the lifetime. You may ask, why a second struct and trait? This is very similar to the XrpcRequest trait, which is implemented on the request struct itself, after all.
Time for magic
The reason is that lifetime when combined with the constraints Axum puts on extractors. Because the request type includes a lifetime, if we were to attempt to implement FromRequest directly for XrpcRequest, the trait would require that XrpcRequest be implemented for all lifetimes, and also apply an effective DeserializeOwned bound, even if we were to specify the 'static lifetime as we do. And of course XrpcRequest is implemented for one specific lifetime, 'a, the lifetime of whatever it's borrowed from. Meanwhile XrpcEndpoint has no lifetime itself, but instead carries the lifetime on the Request associated type. This allows us to do the following implementation, where ExtractXrpc<E> has no lifetime itself and contains an owned version of the deserialized request. And we can then implement FromRequest for ExtractXrpc<R>, and put the for<'any> bound on the IntoStatic trait requirement in a where clause, where it works perfectly. In combination with the code generation in jacquard-lexicon, this is the full implementation of Jacquard's Axum XRPC request extractor. Not so bad.
;
Jacquard then also provides an additional utility to round things out, using the associated PATH constant to put the handler for your XRPC request at the right spot in your router.
/// Conversion trait to turn an XrpcEndpoint and a handler into an axum Router
Which then lets the Axum router for Weaver's Index look like this (truncated for length):
Each of the handlers is a fairly straightforward async function that takes AppState, the XrpcExtractor, and an extractor and validator for service auth, which allows it to be accessed through via your PDS via the atproto-proxy header, and return user-specific data, or gate specific endpoints as requiring authentication.
And so yeah, the actual HTTP server part of the index was dead-easy to write. The handlers themselves are some of them fairly long functions, as they need to pull together the required data from the database over a couple of queries and then do some conversion, but they're straightforward. At some point I may end up either adding additional specialized view tables to the database or rewriting my queries to do more in SQL or both, but for now it made sense to keep the final decision-making and assembly in Rust, where it's easier to iterate on.
Service Auth
Service Auth is, for those not familiar, the non-OAuth way to talk to an XRPC server other than your PDS with an authenticated identity. It's the method the Bluesky AppView uses. There are some downsides to proxying through the PDS, like delay in being able to read your own writes without some PDS-side or app-level handling, but it is conceptually very simple. The PDS, when it pipes through an XRPC request to another service, validates authentication, then generates a short-lived JWT, signs it with the user's private key, and puts it in a header. The service then extracts that, decodes it, and validates it using the public key in the user's DID document. Jacquard provides a middleware that can be used to gate routes based on service auth validation and it also provides an extractor. Initially I provided just one where authentication is required, but as part of building the index I added an additional one for optional authentication, where the endpoint is public, but returns user-specific information when there is an authenticated user. It returns this structure.
Ultimately I want to provide a similar set of OAuth extractors as well, but those need to be built, still. If I move away from service proxying for the Weaver index, they will definitely get written at that point.
I mentioned some bug-fixing in Jacquard was required to make this work. There were a couple of oversights in the
DidDocumentstruct and a spot I had incorrectly held a tracing span across an await point. Also, while using theslingshot_resolverset of options forJacquardResolveris great under normal circumstances (and normally I default to it), the mini-doc does NOT in fact include the signing keys, and cannot be used to validate service auth.I am not always a smart woman.
Why not go full magic?
One thing the Jacquard service auth validation extractor does not provide is validation of that jti nonce. That is left as an exercise for the server developer, to maintain a cache of recent nonces and compare against them. I leave a number of things this way, and this is deliberate. I think this is the correct approach. As powerful as "magic" all-in-one frameworks like Dioxus (or the various full-stack JS frameworks) are, the magic usually ends up constraining you in a number of ways. There are a number of awkward things in the front-end app implementation which are downstream of constraints Dioxus applies to your types and functions in order to work its magic.
There are a lot of possible things you might want to do as an XRPC server. You might be a PDS, you might be an AppView or index, you might be some other sort of service that doesn't really fit into the boxes (like a Tangled knot server or Streamplace node) you might authenticate via service auth or OAuth, communicate via the PDS or directly with the client app. And as such, while my approach to everything in Jacquard is to provide a comprehensive box of tools rather than a complete end-to-end solution, this is especially true on the server side of things, because of that diversity in requirements, and my desire to not constrain developers using the library to work a certain way, so that they can build anything they want on atproto.
If you haven't read the Not An AppView entry, here it is. I might recommend reading it, and some other previous entries in that notebook, as it will help put the following in context.

If you've been to this site before, you maybe noticed it loaded a fair bit more quickly this time. That's not really because the web server creating this HTML got a whole lot better. It did require some refactoring, but it was mostly in the vein of taking some code and adding new code that did the same thing gated behind a cargo feature. This did, however, have the side effect of, in the final binary, replacing functions that are literally hundreds of lines, that in turn call functions that may also be hundreds of lines, making several cascading network requests, with functions that look like this, which make by and large a single network request and return exactly what is required.
Of course the reason is that I finally got round to building the Weaver AppView. I'm going to be calling mine the Index, because Weaver is about writing and I think "AppView" as a term kind of sucks and "index" is much more elegant, on top of being a good descriptor of what the big backend service now powering Weaver does. at://did:plc:ragtjsm2j2vknwkz3zp4oxrd/app.bsky.feed.post/3lyucxfxq622w For the uninitiated, because I expect at least some people reading this aren't big into AT Protocol development, an AppView is an instance of the kind of big backend service that Bluesky PBLLC runs which powers essentially every Bluesky client, with a few notable exceptions, such as Red Dwarf, and (partially, eventually more completely) Blacksky. It listens to the Firehose event stream from the main Bluesky Relay and analyzes the data which comes through that pertains to Bluesky, producing your timeline feeds, figuring out who follows you, who you block and who blocks you (and filtering them out of your view of the app), how many people liked your last post, and so on. Because the records in your PDS (and those of all the other people on Bluesky) need context and relationship and so on to give them meaning, and then that context can be passed along to you without your app having to go collect it all. at://did:plc:uu5axsmbm2or2dngy4gwchec/app.bsky.feed.post/3lsc2tzfsys2f It's a very normal backend with some weird constraints because of the protocol, and in it's practice the thing that separates the day-to-day Bluesky experience from the Mastodon experience the most. It's also by far the most centralising force in the network, because it also does moderation, and because it's quite expensive to run. A full index of all Bluesky activity takes a lot of storage (futur's Zeppelin experiment detailed above took about 16 terabytes of storage using PostgreSQL for the database and cost $200/month to run), and then it takes that much more computing power to calculate all the relationships between the data on the fly as new events come in and then serve personalized versions to everyone that uses it.
It's not the only AppView out there, most atproto apps have something like this. Tangled, Streamplace, Leaflet, and so on all have substantial backends. Some (like Tangled) actually combine the front end you interact with and the AppView into a single service. But in general these are big, complicated persistent services you have to backfill from existing data to bootstrap, and they really strongly shape your app, whether they're literally part of the same executable or hosted on the same server or not. And when I started building Weaver in earnest, not only did I still have a few big unanswered questions about how I wanted Weaver to work, how it needed to work, I also didn't want to fundamentally tie it to some big server, create this centralising force. I wanted it to be possible for someone else to run it without being dependent on me personally, ideally possible even if all they had access to was a static site host like GitHub Pages or a browser runtime platform like Cloudflare Workers, so long as someone somewhere was running a couple of generic services. I wanted to be able to distribute the fullstack server version as basically just an executable in a directory of files with no other dependencies, which could easily be run in any container hosting environment with zero persistent storage required. Hell, you could technically serve it as a blob or series of blobs from your PDS with the right entry point if I did my job right.
I succeeded.
Well, I don't know if you can serve weaver-app purely via com.atproto.sync.getBlob request, but it doesn't need much.
Constellation
at://did:plc:ttdrpj45ibqunmfhdsb4zdwq/app.bsky.feed.post/3m6pckslkt222 Ana's leaflet does a good job of explaining more or less how Weaver worked up until now. It used direct requests to personal data servers (mostly mine) as well as many calls to Constellation and Slingshot, and some even to UFOs, plus a couple of judicious calls to the Bluesky AppView for profiles and post embeds. at://did:plc:hdhoaan3xa3jiuq4fg4mefid/app.bsky.feed.post/3m5jzclsvpc2c
The three things linked above are generic services that provide back-links, a record cache, and a running feed of the most recent instances of all lexicons on the network, respectively. That's more than enough to build an app with, though it's not always easy. For some things it can be pretty straightforward. Constellation can tell you what notebooks an entry is in. It can tell you which edit history records are related to this notebook entry. For single-layer relationships it's straightforward. However you then have to also fetch the records individually, because it doesn't provide you the records, just the URIs you need to find them. Slingshot doesn't currently have an endpoint that will batch fetch a list of URIs for you. And the PDS only has endpoints like com.atproto.repo.listRecords, which gives you a paginated list of all records of a specific type, but doesn't let you narrow that down easily, so you have to page through until you find what you wanted.
This wouldn't be too bad if I was fine with almost everything after the hostname in my web URLs being gobbledegook record keys, but I wanted people to be able to link within a notebook like they normally would if they were linking within an Obsidian Vault, by name or by path, something human-readable. So some queries became the good old N+1 requests, because I had to list a lot of records and fetch them until I could find the one that matched. Or worse still, particularly once I introduce collaboration and draft syncing to the editor. Loading a draft of an entry with a lot of edit history could take 100 or more requests, to check permissions, find all the edit records, figure out which ones mattered, publish the collaboration session record, check for collaborators, and so on. It was pretty slow going, particularly when one could not pre-fetch and cache and generate everything server-side on a real CPU rather than in a browser after downloading a nice chunk of WebAssembly code. My profile page alpha.weaver.sh/nonbinary.computer often took quite some time to load due to a frustrating quirk of Dioxus, the Rust web framework I've used for the front-end, which prevented server-side rendering from waiting until everything important had been fetched to render the complete page on that specific route, forcing me to load it client-side.
Some stuff is just complicated to graph out, to find and pull all the relevant data together in order, and some connections aren't the kinds of things you can graph generically. For example, in order to work without any sort of service that has access to indefinite authenticated sessions of more than one person at once, Weaver handles collaborative writing and publishing by having each collaborator write to their own repository and publish there, and then, when the published version is requested, figuring out which version of an entry or notebook is most up-to-date, and displaying that one. It matches by record key across more than one repository, determined at request time by the state of multiple other records in those users' repositories.

Shape of Data
All of that being said, this was still the correct route, particularly for me. Because not only does this provide a powerful fallback mode, built-in protection against me going AWOL, it was critical in the design process of the index. My friend Ollie, when talking about database and API design, always says that, regardless of the specific technology you use, you need to structure your data based on how you need to query into it. Whatever interface you put in front of it, be it GraphQL, SQL, gRPC, XRPC, server functions, AJAX, literally any way that you can have the part of your app that people interact with pull the specific data they want from where it's stored, how well that performs, how many cycles your server or client spends collecting it, sorting it, or waiting on it, how much memory it takes, how much bandwidth it takes, depends on how that data is shaped, and you, when you are designing your app and all the services that go into it, get to choose that shape.
Bluesky developers have said that hydrating blocks, mutes, and labels and applying the appropriate ones to the feed content based on the preferences of the user takes quite a bit of compute at scale, and that even the seemingly simple Following feed, which is mostly a reverse-chronological feed of posts by people you follow explicitly (plus a few simple rules), is remarkably resource-intensive to produce for them. The extremely clever string interning and bitmap tricks implemented by a brilliant engineer during their time at Bluesky are all oriented toward figuring out the most efficient way to structure the data to make the desired query emerge naturally from it. 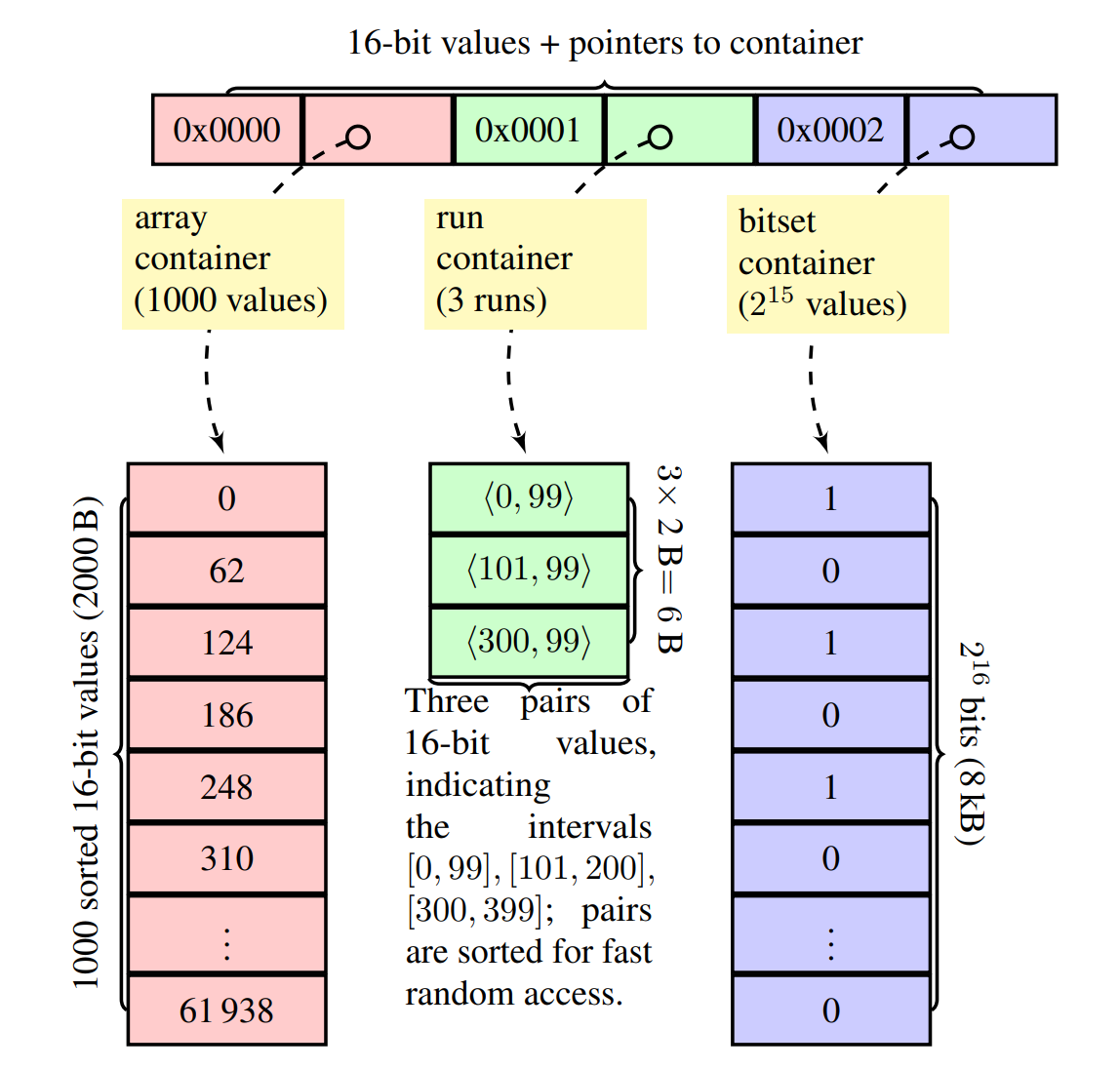
It's intuitive that this matters a lot when you use something like RocksDB, or FoundationDB, or Redis, which are fundamentally key-value stores. What your key contains there determines almost everything about how easy it is to find and manipulate the values you want. Fig and I have had some struggles getting a backup of their Constellation service running in real-time and keeping up with Jetstream on my home server, because the only storage on said home server with enough free space for Constellation's full index is a ZFS pool that's primarily hard-drive based, and the way the Constellation RocksDB backend storage is structured makes processing delete events extremely expensive on a hard drive where seek times are nontrivial. On a Pi 4 with an SSD, it runs just fine. at://did:plc:44ybard66vv44zksje25o7dz/app.bsky.feed.post/3m7e3hnyh5c2u But it's a problem for every database. Custom feed builder service graze.social ran into difficulties with Postgres early on in their development, as they rapidly gained popularity. They ended up using the same database I did, Clickhouse, for many of the same reasons. at://did:plc:i6y3jdklpvkjvynvsrnqfdoq/app.bsky.feed.post/3m7ecmqcwys23 And while thankfully I don't think that a platform oriented around long-form written content will ever have the kinds of following timeline graph write amplification problems Bluesky has dealt with, even if it becomes successful beyond my wildest dreams, there are definitely going to be areas where latency matters a ton and the workload is very write-heavy, like real-time collaboration, particularly if a large number of people work on a document simultaneously, even while the vast majority of requests will primarily be reading data out.
One reason why the edit records for Weaver have three link fields (and may get more!), even though it may seem a bit redundant, is precisely because those links make it easy to graph the relationships between them, to trace a tree of edits backward to the root, while also allowing direct access and a direct relationship to the root snapshot and the thing it's associated with.
In contrast, notebook entry records lack links to other parts of the notebook in and of themselves because calculating them would be challenging, and updating one entry would require not just updating the entry itself and notebook it's in, but also neighbouring entries in said notebook. With the shape of collaborative publishing in Weaver, that would result in up to 4 writes to the PDS when you publish an entry, in addition to any blob uploads. And trying to link the other way in edit history (root to edit head) is similarly challenging.
I anticipated some of these. but others emerged only because I ran into them while building the web app. I've had to manually fix up records more than once because I made breaking changes to my lexicons after discovering I really wanted X piece of metadata or cross-linkage. If I'd built the index first or alongside—particularly if the index remained a separate service from the web app as I intended it to, to keep the web app simple—it would likely have constrained my choices and potentially cut off certain solutions, due to the time it takes to dump the database and re-run backfill even at a very small scale. Building a big chunk of the front end first told me exactly what the index needed to provide easy access to.
You can access it here: index.weaver.sh
ClickHAUS
So what does Weaver's index look like? Well it starts with either the firehose or the new Tap sync tool. The index ingests from either over a WebSocket connection, does a bit of processing (less is required when ingesting from Tap, and that's currently what I've deployed) and then dumps them in the Clickhouse database. I chose it as the primary index database on recommendation from a friend, and after doing a lot of reading. It fits atproto data well, as Graze found. Because it isolates concurrent inserts and selects so that you can just dump data in, while it cleans things up asynchronously after, it does wonderfully when you have a single major input point or a set of them to dump into that fans out, which you can then transform and then read from.
I will not claim that the tables you can find in the weaver repository are especially good database design overall, but they work, they're very much a work in progress, and we'll see how they scale. Also, Tap makes re-backfilling the data a hell of a lot easier.
This is one of three main input tables. One for record writes, one for identity events, and one for account events.
NOT EXISTS raw_records (
did String,
collection LowCardinality(String),
rkey String,
cid String,
-- Repository revision (TID)
rev String,
record JSON,
-- Operation: 'create', 'update', 'delete', 'cache' (fetched on-demand)
operation LowCardinality(String),
-- Firehose sequence number
seq UInt64,
-- Event timestamp from firehose
event_time DateTime64(3),
-- When the database indexed this record
indexed_at DateTime64(3) DEFAULT now64(3),
-- Validation state: 'unchecked', 'valid', 'invalid_rev', 'invalid_gap', 'invalid_account'
validation_state LowCardinality(String) DEFAULT 'unchecked',
-- Whether this came from live firehose (true) or backfill (false)
is_live Bool DEFAULT true,
-- Materialized AT URI for convenience
uri String MATERIALIZED concat('at://', did, '/', collection, '/', rkey),
-- Projection for fast delete lookups by (did, cid)
PROJECTION by_did_cid (
SELECT * ORDER BY (did, cid)
)
)
ENGINE = MergeTree
ORDER BY (collection, did, rkey, event_time, indexed_at);
From here we fan out into a cascading series of materialized views and other specialised tables. These break out the different record types, calculate metadata, and pull critical fields out of the record JSON for easier querying. Clickhouse's wild-ass compression means we're not too badly off replicating data on disk this way. Seriously, their JSON type ends up being the same size as a CBOR BLOB on disk in my testing, though it does have some quirks, as I discovered when I read back Datetime fields and got...not the format I put in. Thankfully there's a config setting for that.  We also build out the list of who contributed to a published entry and determine the canonical record for it, so that fetching a fully hydrated entry with all contributor profiles only takes a couple of
We also build out the list of who contributed to a published entry and determine the canonical record for it, so that fetching a fully hydrated entry with all contributor profiles only takes a couple of SELECT queries that themselves avoid performing extensive table scans due to reasonable choices of ORDER BY fields in the denormalized tables they query and are thus very fast. And then I can do quirky things like power a profile fetch endpoint that will provide either a Weaver or a Bluesky profile, while also unifying fields so that we can easily get at the critical stuff in common. This is a relatively expensive calculation, but people thankfully don't edit their profiles that often, and this is why we don't keep the stats in the same table.
However, this is also why Clickhouse will not be the only database used in the index.
Why is it always SQLite?
When it comes to things like real-time collaboration sessions with almost keystroke-level cursor tracking and rapid per-user writeback/readback, where latency matters and we can't wait around for the merge cycle to produce the right state, don't work well in Clickhouse. But they sure do in SQLite!
If there's one thing the AT Protocol developer community loves more than base32-encoded timestamps it's SQLite. In fairness, we're in good company, the whole world loves SQLite. It's a good fucking embedded database and very hard to beat for write or read performance so long as you're not trying to hit it massively concurrently. Of course, that concurrency limitation does end up mattering as you scale. And here we take a cue from the Typescript PDS implementation and discover the magic of buying, well, a lot more than two of them, and of using the filesystem like a hierarchical key-value store.
This part of the data backend is still very much a work-in-progress and isn't used yet in the deployed version, but I did want to discuss the architecture. Unlike the PDS, we don't divide primarily by DID, instead we shard by resource, designated by collection and record key.
/// A single SQLite shard for a resource
/// Routes resources to their SQLite shards
The hash of the shard key plus the record key gives us the directory where we put the database file for this resource. Ultimately this may be moved out of the main index off onto something more comparable to the Tangled knot server or Streamplace nodes, depending on what constraints we run into if things go exceptionally well, but for now it lives as part of the index. In there we can tee off raw events from the incoming firehose and then transform them into the correct forms in memory, optionally persisted to disk, alongside Clickhouse and probably, for the specific things we want it for with a local scope, faster.
And direct communication, either by using something like oatproxy to swap the auth relationships around a bit (currently the index is accessed via service proxying through the PDS when authenticated) or via an iroh channel from the client, gets stuff there without having to wait for the relay to pick it up and fan it out to us, which then means that users can read their own writes very effectively. The handler hits the relevant SQLite shard if present and Clickhouse in parallel, merging the data to provide the most up-to-date form. For real-time collaboration this is critical. The current iroh-gossip implementation works well and requires only a generic iroh relay, but it runs into the problem every gossip protocol runs into the more concurrent users you have.
The exact method of authentication of that side-channel is by far the largest remaining unanswered question about Weaver right now, aside from "Will anyone (else) use it?"
If people have ideas, I'm all ears.
Future
Having this available obviously improves the performance of the app, but it also enables a lot of new stuff. I have plans for social features which would have been much harder to implement without it, and can later be backfilled into the non-indexed implementation. I have more substantial rewrites of the data fetching code planned as well, beyond the straightforward replacement I did in this first pass. And there's still a lot more to do on the editor before it's done.
I've been joking about all sorts of ambitious things, but legitimately I think Weaver ends up being almost uniquely flexible and powerful among the atproto-based long-form writing platforms with how it's designed, and in particular how it enables people to create things together, and can end up filling some big shoes, given enough time and development effort.
I hope you found this interesting. I enjoyed writing it out. There's still a lot more to do, but this was a big milestone for me.
If you'd like to support this project, here's a GitHub Sponsorship link, but honestly I'd love if you used it to write something.
Dogfooding again
That being said, my experience writing the Weaver front-end and now the index server does leave me wanting a few things. One is a "BFF" session type, which forwards requests through a server to the PDS (or index), acting somewhat like oatproxy (prototype jacquard version of that here courtesy of Nat and Claude). This allows easier reading of your own writes via server-side caching, some caching and deduplication of common requests to reduce load on the PDS and roundtrip time. If the seession lives server-side it allows longer-lived confidential sessions for OAuth, and avoids putting OAuth tokens on the client device.
Once implemented, I will likely refactor the Weaver app to use this session type in fullstack-server mode, which will then help dramatically simplify a bunch of client-side code. The refactored app will likely include an internal XRPC "server" of sorts that will elide differences between the index's XRPC APIs and the index-less flow. With the "fullstack-server" and "use-index" features, the client app running in the browser will forward authenticated requests through the app server to the index or PDS. With "fullstack-server" only, the app server itself acts like a discount version of the index, implemented via generic services like Constellation. Performance will be significantly improved over the original index-less implementation due to better caching, and unifying the cache. In client-only mode there are a couple of options, and I am not sure which is ultimately correct. The straightforward way as far as separation of concerns goes would be to essentially use a web worker as intermediary and local cache. That worker would be compiled to either use the index or to make Constellation and direct PDS requests, depending on the "use-index" feature. However that brings with it the obvious overhead of copying data from the worker to the app in the default mode, and I haven't yet investigated how feasible the available options which might allow zero-copy transfer via SharedArrayBuffer are. That being said, the real-time collaboration feature already works this way (sans SharedArrayBuffer) and lag is comparable to when the iroh connection was handled in the UI thread.
A fair bit of this is somewhat new territory for me, when it comes to the browser, and I would be very interested in hearing from people with more domain experience on the likely correct approach.
On that note, one of my main frustrations with Jacquard as a library is how heavy it is in terms of compiled binary size due to monomorphization. I made that choice, to do everything via static dispatch, but when you want to ship as small a binary as possible over the network, it works against you. On WASM I haven't gotten a great number of exactly the granular damage, but on x86_64 (albeit with less aggressive optimisation for size) we're talking kilobytes of pure duplicated functions for every jacquard type used in the application, plus whatever else.
0.0% 0.0% 9.3KiB weaver_app
0.0% 0.0% 9.2KiB loro_internal <Transaction>_commit
0.0% 0.0% 9.2KiB weaver_app <Fetcher as AgentSessionExt>::
0.0% 0.0% 9.2KiB weaver_app <Fetcher as AgentSessionExt>::
0.0% 0.0% 9.2KiB weaver_app <Fetcher as AgentSessionExt>::
0.0% 0.0% 9.2KiB weaver_renderer <JacquardResolver as IdentityResolver>::
0.0% 0.0% 9.2KiB weaver_app <Client as AgentSessionExt>::
0.0% 0.0% 9.2KiB weaver_app <Client as AgentSessionExt>::
0.0% 0.0% 9.2KiB weaver_app <Client as AgentSessionExt>::
0.0% 0.0% 9.2KiB weaver_app <Client as AgentSessionExt>::
0.0% 0.0% 9.2KiB weaver_app <Client as AgentSessionExt>::
0.0% 0.0% 9.2KiB weaver_app <Client as AgentSessionExt>::
0.0% 0.0% 9.2KiB weaver_app <Client as AgentSessionExt>::
0.0% 0.0% 9.2KiB weaver_app <Client as AgentSessionExt>::
0.0% 0.0% 9.2KiB weaver_app <Client as AgentSessionExt>::
0.0% 0.0% 9.2KiB resvg <Vp8Decoder>loop_filter
0.0% 0.0% 9.2KiB miette <GraphicalReportHandler>
0.0% 0.0% 9.1KiB miette <GraphicalReportHandler>
0.0% 0.0% 9.1KiB weaver_app ::
I've taken a couple stabs at refactors to help with this, but haven't found a solution that satisfies me, in part because one of the problems in practice is of course overhead from serde_json monomorphization. Unfortunately, the alternatives trade off in frustrating ways. facet has its own binary size impacts and facet-json is missing a couple of critical features to work with atproto JSON data (internally-tagged enums, most notably). Something like simd-json or serde_json_borrow is fast and can borrow from the buffer in a way that is very useful to us (and honestly I intend to swap to them for some uses at some point), but serde_json_borrow only provides a value type, and I would then be uncertain at the monomorphization overhead of transforming that type into jacquard types. The serde implementation for simd-json is heavily based on serde_json and thus likely has much the same overhead problem. And miniserde similarly lacks support for parts of JSON that atproto data requires (enums again). And writing my own custom JSON parser that deserializes into Jacquard's Data or RawData types (from where it can then be deserialized more simply into concrete types, ideally with much less code duplication) is not a project I have time for, and is on the tedious side of the kind of thing I enjoy, particularly the process of ensuring it is sufficiently robust for real-world use, and doesn't perform terribly.
dyn compatibility for some of the Jacquard traits is possible but comes with its own challenges, as currently Serialize is a supertrait of XrpcRequest, and rewriting around removing that bound that is both a nontrivial refactor (and a breaking API change, and it's not the only barrier to dyn compatibility) and may not actually reduce the number of copies of get_record() in the binary as much as one would hope. Now, if most of the code could be taken out of that and put into a function that could be totally shared between all implementations or at least most, that would be ideal but the solution I found prevented the compiler from inferring the output type from the request type, it decoupled those two things too much. Obviously if I were to do a bunch of cursed internal unsafe rust I could probably make this work, but while I'm comfortable writing unsafe Rust I'm also conscious that I'm writing Jacquard not just for myself. My code will run in situations I cannot anticipate, and it needs to be as reliable as possible and as usable as possible. Additional use of unsafe could help with the latter (laundering lifetimes would make a number of things in Jacquard's main code paths much easier, both for me and for users of the library) but at potential cost to the former if I'm not smart enough or comprehensive enough in my testing.
So I leave you, dear reader, with some questions this time.
What choices make sense here? For Jacquard as a library, for writing web applications in Rust, and so on. I'm pretty damn good at this (if I do say so myself, and enough other people agree that I must accept it), but I'm also one person, with a necessarily incomplete understanding of the totality of the field.